ブラウザだけで動くdbt(っぽい)環境「DuckBT」を作った話【DuckDB-WASM】
1. はじめに
今回は、「ブラウザを開いた瞬間からSQLを書き始められる、サーバーレスなdbtライク環境」 である 『DuckBT』 を開発・公開したので、その技術的な裏側と、無駄にこだわったポイントについて紹介します。
2. DuckBTとは?
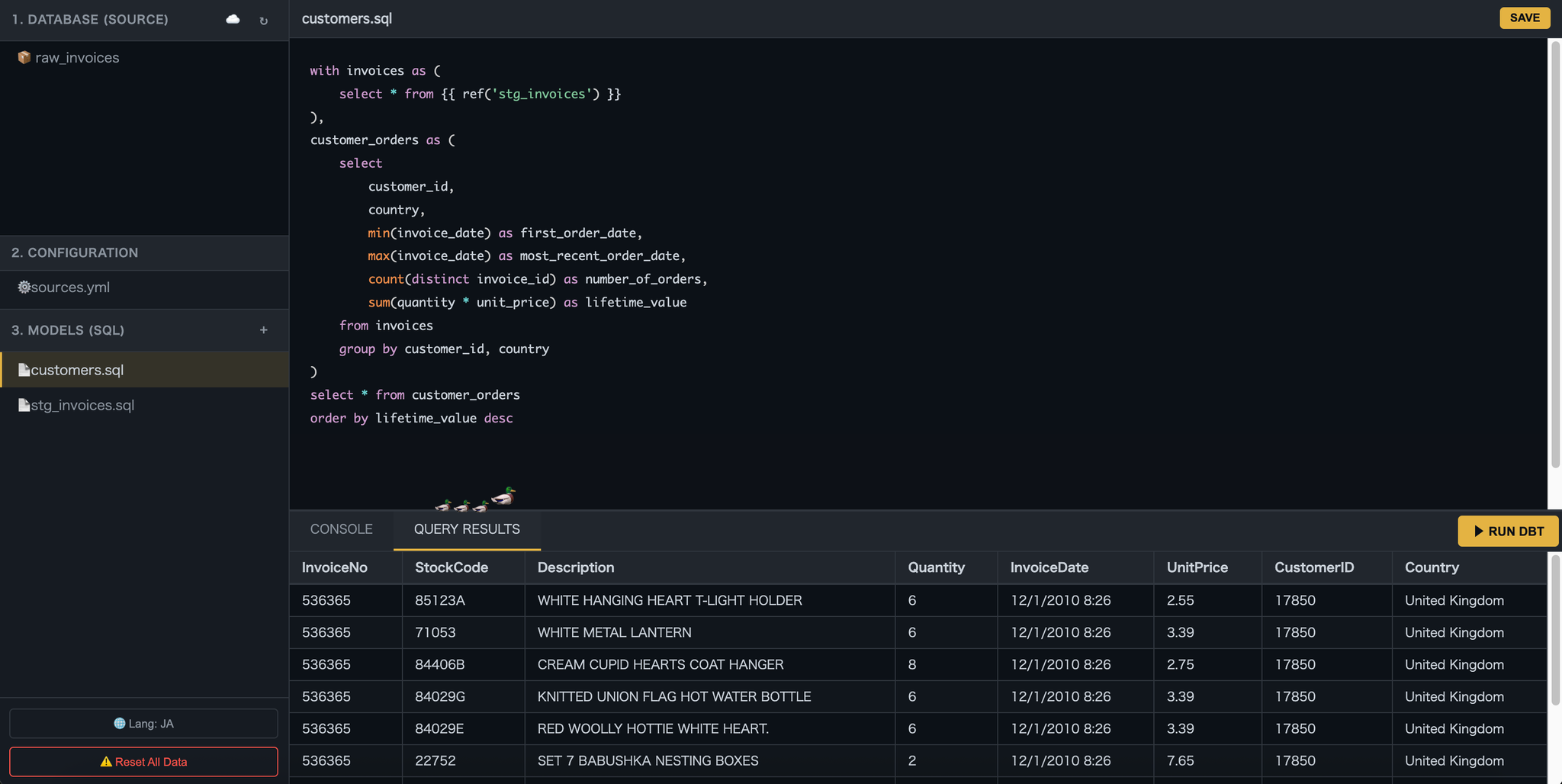
まずは動いているものを見てください。
- Repository: https://github.com/takimo/duckbt
DuckBT は、ブラウザ上で動作する軽量なSQL開発環境です。
Pythonの仮想環境も、クラウドDWH(Snowflake/BigQuery)のクレデンシャルも不要。ただURLを開くだけで、dbtのような や を使ったデータモデリングを体験できます。
3. なぜ作ったのか(真面目な動機)
普段、dbtの初学者の方をサポートしたり、ハンズオンを行ったりする中で、どうしても高いハードルになるのが 「環境構築」 でした。
- を入れるためのPython環境問題
- DWHのアカウント開設とクレジットカード登録
- の設定エラー
「dbtの概念(DAGやSQLによる変換)を理解したいだけなのに、そこにたどり着く前に疲弊してしまう」というケースを何度も見てきました。
そこで、「URLを開くだけで、自分の手持ちのCSVを使って、さっとdbtごっこができる環境」 があれば、教育用やプロトタイピングに最適なのではないかと思い、開発に着手しました。
4. 技術的な仕組み
DuckBTは、モダンなWeb技術を組み合わせて作られています。
🚀 エンジン:DuckDB-WASM
このツールの心臓部は DuckDB-WASM です。
分析用データベースであるDuckDBをWebAssemblyにコンパイルしたもので、ブラウザのメモリ上で高速にSQLを実行できます。これにより、サーバーサイドの実装を一切行わずに、リッチなデータ処理環境を実現しました。
🛠 コンパイラ:簡易的なJinja2再現
dbtの肝である や のコンパイルには、JavaScript製のテンプレートエンジン Nunjucks を採用しました。
正直に言うと、 による依存関係の解決(DAGの構築)は、時間がなくてかなり簡易的な(雑な)実装になっています。「 で始まるモデルを先に実行する」といったヒューリスティックなソートで動かしていますが、雰囲気は十分に味わえます。
💾 データロード機能
「自分のデータで遊びたい」という要望に応えるため、外部URL(GitHub Rawなど)からのCSVロード機能を実装しました。CORS(Cross-Origin Resource Sharing)の制約を回避するため、必要に応じてプロキシを経由するオプションも用意しています。
5. 🛠️ 技術的な裏側:どうやって動いているのか?
DuckBTのコアロジックは、実は驚くほどシンプルです。
本家のdbtがPythonで行っている複雑な処理を、ブラウザ(JavaScript)上で再現するために、大きく以下の3つのステップでSQLを処理しています。
- Jinjaの解決: や を実際のテーブル名に置換
- 依存関係の解析: 簡易的なDAG(有向非巡回グラフ)の構築
- 実行: DuckDB-WASMでクエリを投げる
それぞれの実装の裏側を少しだけお見せします。
① ブラウザでJinjaを動かす
本家dbtはPython製のJinja2を使っていますが、ブラウザで同じことをするために、Mozilla製のテンプレートエンジン Nunjucks を採用しました。
関数を定義して、物理テーブル名を返すだけのシンプルな実装です。
② 簡易DAGソルバー(という名の力技)
dbtの強力な機能の一つは、モデル間の依存関係を解析して実行順序を自動で決めてくれるところです。
これを真面目に実装するにはSQLのAST(抽象構文木)解析が必要ですが、今回はアドベントカレンダーの締切駆動開発だったため、「ファイル名の接頭辞で決める」 という大胆なショートカットをしました。
「これじゃ循環参照に対応できないじゃん!」というツッコミは甘んじて受け入れます。トポロジカルソートの実装PR、お待ちしています(笑)
③ DuckDB-WASMでビューを作成
コンパイルされたSQLは、DuckDBに対して 文として投げられます。
通常の ではなく として作成することで、後続のモデルが前のモデルの結果をテーブルのように参照できるようになります。
これだけで、ブラウザの中で連鎖的にデータ変換が進む「dbtっぽい体験」が完成しました。DuckDB-WASMの処理能力が凄まじいため、数万行程度のデータなら、ネットワーク遅延ゼロで一瞬で終わるのが快感です。
6. 苦労した点:OPFSとの戦いと敗北
開発中に最も技術的負債となったのが、ファイルシステムの永続化 です。
当初は、数GBクラスの巨大なCSVも扱えるように、ブラウザの OPFS (Origin Private File System) を利用してデータを永続化しようと試みました。
しかし、DuckDB-WASMとOPFSの組み合わせはまだ発展途上で、「ファイルロックが解放されずにデータベースが破損する」「ブラウザのリロードで不整合が起きる」といったエラーをどうしても倒しきれませんでした。
アドベントカレンダーの締切も迫っていたため、今回は泣く泣く LocalStorage ベースの構成に切り替えました。そのため、扱えるデータ量はブラウザのストレージ制限(数MB程度)に依存しますが、その分動作は非常に安定しました。
7. 無駄にこだわったポイント(愛)
機能とは関係ない部分にこそ、魂は宿ります。
🦆 妻監修!アヒルの小隊行進
画面下部を歩くアヒルのアニメーションには特に力を入れました。
「ただ歩くだけじゃつまらない」という妻の監修のもと、CSSアニメーションとJSを駆使して「親アヒルの後ろを子アヒルがついてくる」「ランダムで子アヒルの数が増減する」「折り返し地点でちゃんと隊列が反転する」という挙動を実装しています。
コードを書くのに疲れたら、ぼーっと眺めて癒やされてください。
💬 架空のレジェンドたちの名言
"モデルは芸術だが、デプロイは戦争だ。" — A. Kim "真実は dbt run の先にある。" — Unknown AE
リロードするたびに変わるので、ぜひコンプリートを目指してください。
8. コントリビュート待ってます!(助けてください)
正直に白状しますと、アドベントカレンダーの締切駆動開発だったため、「やりたかったけど実装しきれなかった機能」 が山のようにあります。
- OPFS (Origin Private File System) 対応:
- ブラウザ上で数GBのCSVをさばく夢を見ていましたが、ファイルロックのエラーと格闘した末に敗北しました。誰かDuckDB-WASMとOPFSの仲直りをさせてあげてください。
- まともなDAG(有向非巡回グラフ)の解決:
- 現在の依存関係解決ロジックは「 がついてるやつを先にやる」という、あまりにも牧歌的なアルゴリズムで動いています。トポロジカルソートを実装してくれる数学が得意な方、募集中です。
- dbt test 機能:
- に書いたテストが走ったら最高ですよね。まだ影も形もありません。
DuckBTは、「とりあえず動くプロトタイプ」 です。
もし「このバグ直してやったぞ」「DAGソルバー書いたよ」という猛者がいらっしゃいましたら、軽い気持ちでIssueやPRをいただけると泣いて喜びます!
一緒に最強の「ブラウザdbtごっこ環境」を作りましょう!🦆
- GitHub Repository: https://github.com/takimo/duckbt
9. おわりに
DuckBTは、dbtの機能を完全に再現したものではありませんが、「データモデリングの楽しさ」を最速で体験できるサンドボックスとしては、面白いものができたと自負しています。
コミュニティオーガナイザーとして、これからも「データエンジニアリングを楽しく、身近にする」活動を続けていきたいと思います。
Happy Modeling! 🦆