なぜAI AgentにSQLを直接触らせず、dbt showを使わせたのか

背景と課題
特殊な性質を持つデータパイプライン
データパイプラインと一口に言っても、その用途や役割によって大きく性格が異なります。
例えば、分析用のシンプルなパイプラインもあれば、CRMやマスタデータなど複数のデータソースを組み合わせ、新しいデータを生成するような複雑なパイプラインも存在します。
そうした生成系のパイプラインには、いくつかの特徴があります。
- データの早期バリデーション
想定外のデータは生成せず、下流に流さない仕組みが求められる。
- イシュー解決型のロジック
左から右に単純にデータを流すのではなく、課題を解決するために新しいデータを生成したり、逆に不正なデータを除外する処理も組み込まれる。
つまり、単に「流す」だけではなく、正確性・安全性を担保しながらデータを生成・加工する性質があるため、調査や検証の手順も特殊になります。
ちなみに自分が勤めている10Xの場合は以下ような商品マスタのパイプラインがあったりします
属人化していた商品データ調査
属人的な“手作業トレース”に依存していたため、知識依存・再現性の低さ・時間コストが目立ちました。
- 専門知識が前提(テーブル構造/依存関係)
- 人・ケースごとに手順が揺れる
- 調査完了までに時間を要する(ステップバイステップでの実行、クエリの待ち時間等)
AIエージェントに任せてみたら…
素のSQLをそのまま書かせる運用では、次のような摩擦が顕在化します。
- フルパス未把握による失敗や、重いクエリ化によるコスト増
- 説明のためのスキーマ開示が増え、コンテキストが肥大
- 稀に DDL を含む不適切な生成もあり得る
→ 「素のSQLのみ」は設計・運用上の配慮が多い
dbtのおさらい
- 単なる SQL 実行ツールではなく、テーブルを抽象化した「モデル」として管理する仕組み
- 例: → 実際には BigQuery 上の に解決される
- コードは Git 管理。依存関係(DAG)やマクロ・変数でロジックを一元管理できる
ポイント
- 開発者は「モデル名」だけで操作できる
- フルパスや依存関係を知らなくてもよい
- AI にも同じレイヤーで触らせる方が効率的なのではないか
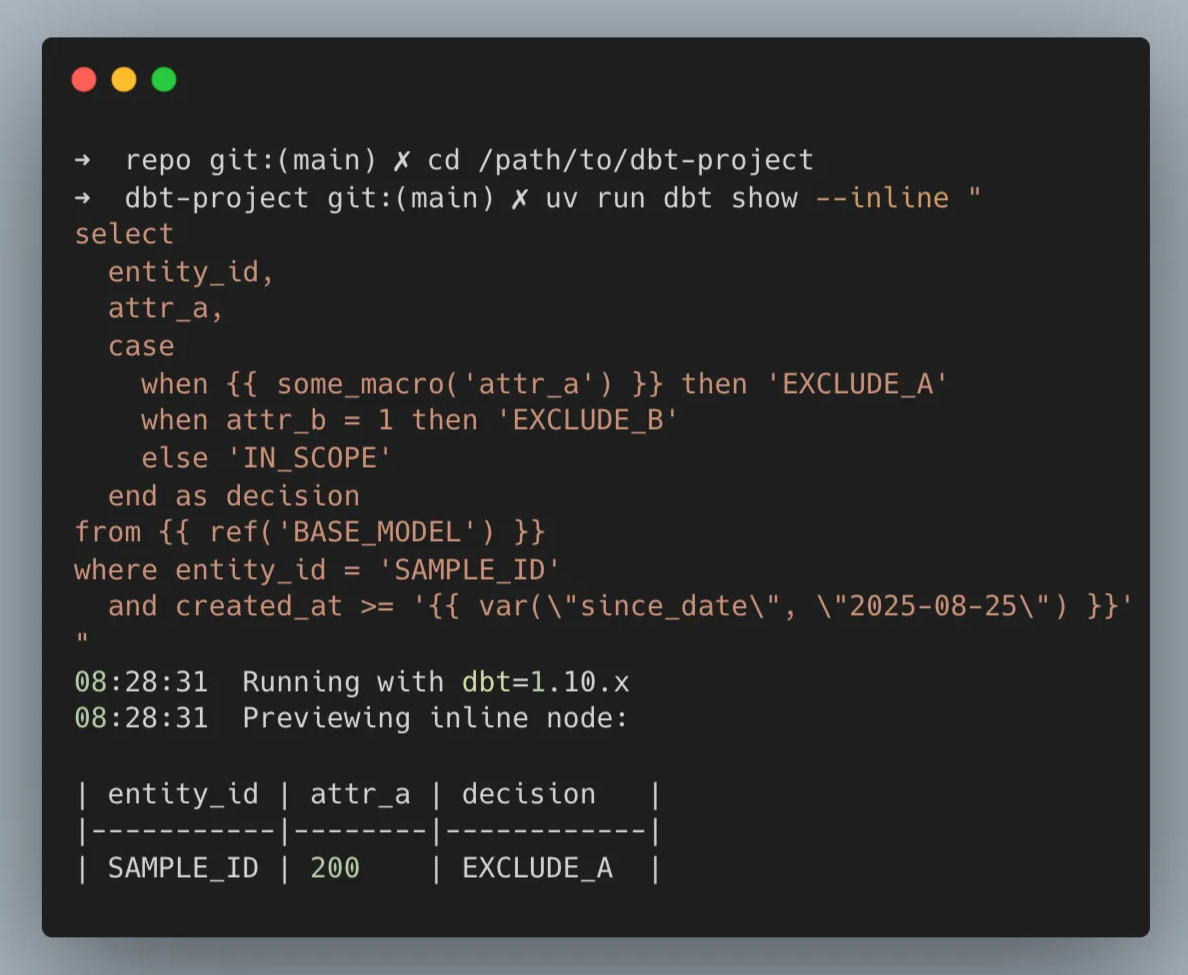
dbt show を活用した解決策
なぜ dbt show なのか?
dbt が持つ抽象化情報をそのまま使って SELECT を実行できるコマンド。
メリット:
- 安全:SELECT 限定、副作用なし
- 抽象化を活用: / で DAG を辿れる
- 再現性:マクロ・変数を解決して実行するので、人間が見るのと同じロジックで確認できる
- 情報の受け渡し最小化:AI にフルパスや複雑なスキーマを教える必要がない
👉 AI エージェントに与える情報を減らせる(=無駄なコンテキストを渡さなくていい)
関連ナレッジ:AIエージェント実行のガードレール
同僚のYoshidaさんから「AIにbq queryを直接実行させるのは危険な場合がある」というフィードバックをもらいました。実際、bq queryはSELECTだけでなくDDL/DMLまで可能で副作用リスクがあります。
記事ではLLMに危険クエリを判定させたり、SAを最小権限にしたり、サンドボックス環境で隔離する方法が紹介されています。
dbt showコマンドのセキュリティリスク
dbt showコマンドにも同様のリスクがあることが判明しました:
- オプション:指定したモデルのSELECTクエリのみ実行(比較的安全)
- オプション:任意のSQLが実行できてしまうため現状リスクがある
例えば以下のようなクエリが実行できてしまいます:
これはdbt showというコマンドの本来のプレビュー目的から逸脱しているため、dbt-coreにissueとして報告済みです
[Bug] dbt show --inline-direct allows execution of non-SELECT statements
Updated Nov 25, 2025
暫定対策:ラッパーコマンドの実装例
issueが解決されるまでは、dbt showをそのまま実行させるのではなく、入力されたクエリをサブクエリでラップするようなラッパーコマンドを使用することを推奨します。
以下に簡単な実装例を示します:
使用例:
上記のこともあるから、実行する環境やリスクも考えながら、安全に使うためのガードレールも合わせて大切です。またClaude Codeには実行許可コマンドのルール設定機能がありますが、Clineにも実装されると良いですね(issueにあげられている)
安全に活用できるようなガードレールを施しつつ、AIエージェントの力を最大限に活用していきましょう。
実際の調査ワークフローと工夫
1. 依頼の仕方(ユーザー目線)
実際には、こんな風に書くだけで AI に商品調査を依頼できます
- 書き方はシンプル
- 指定した商品IDの調査を、AIがドキュメント化されたワークフローに沿って自動で実施
2. 調査ワークフロー(AIが実行する内容)
AIが参照するのは に書いた手順です。
前提
- ユーザーから「商品が出ない/期待する売価・在庫でない」といった問い合わせが来る
- 本ワークフローは「商品が出ていない原因」を探るフローに特化
調査のアプローチ
- 下流 → 上流に順に確認していく
- marts_catalog(最終的に表示される商品データ)
- dim_product(商品の主要データ)
- fact_price(売価情報)
- fact_stock(在庫情報)
→ marts_catalog になければ絶対に表示されない → まずここを調査の起点にする
調査データ保存の工夫
- 調査ごとにブランチ単位で保存
- ローカルにログが残るため、後から調査過程をレビューできる
調査コマンドの制御
- dbt showを必ず使うように固定 → 「素のSQL直書き」させない
- を使うのでテーブルのフルパスをAIに教える必要なし
- DAGを辿って再帰的に調査可能
3. 工夫したポイント
- ドキュメントドリブン化:手順をmd化し、AIがそれを忠実に実行するだけでよい
- 情報の最小化:AIには商品IDや日時といった最低限だけ渡せばよく、余計なスキーマ知識は不要
- 再現性:調査データをtxtに保存 → 後から人間がチェックできる
- 拡張性:ClaudeでもDevinでも、同じドキュメントを読ませれば再利用できる
4. デモイメージ
- ユーザー「この商品IDの商品が出ないので調べて」
- AI → を show → なければ → → の順で調査
- 除外ロジックがあればSQLを再現しつつ確認
- 最後にマークダウンでレポートを生成してもらう
完成したワークフローのプロンプト
成果と学び
1. 属人化した調査を再現可能に
- 今までは人が DAG を頭の中でたどって SQL を書いていた
- dbt show を AI エージェントに使わせることで、調査フローを 機械的・再現可能 な形に落とし込めた
- 調査レポートを Markdown 出力し、Notion にそのまま転記できる → ナレッジ化が進む
2. 安全で最小限のコンテキストで AI を動かせる
- AIに素のSQLを書かせる場合 → フルパスや細かいスキーマ知識を逐一教える必要があり、AI に渡す情報が広がりやすい
- dbt show経由 → dbt が抽象化したモデル名・DAG・マクロをそのまま使える
- AI に余計なコンテキストを与えず、人間と同じ視点でデータ調査できる
3. 今後の発展:dbt MCP Server との接続
- dbt Labs が発表した dbt MCP Server は、dbt プロジェクトの構造・ドキュメント・Semantic Layer を AI ワークフローに直接提供できる仕組み
- できること(現状):
- Data Discovery: どんなモデルがあるか、カラム情報や依存関係を LLM に渡せる
- Semantic Layer Querying: 定義済みメトリクスを LLM がそのまま呼び出せる
- Project Execution: や を会話から呼べる
- 今回の「dbt show を AI に使わせる実験」は、MCP が描く世界観の 手前の実用アプローチ
- 将来的には「AI エージェントに MCP を経由して dbt プロジェクト全体を安全に探索・利用させる」方向に進めそう
モデル/カラムのドキュメントやテストが充実しているほど、AI に渡せるコンテキストの質が上がる。調査の精度や説明可能性の向上のためにも、ドキュメントとテストの拡充は重要。